
The Modeler allows you to process Application objects (e.g., databases, cubes, partitions, and Dimensions) through the UI when needed. If a process task needs to be scheduled, we can use a SQL Agent Job.
Example - Process Partition
1. Open SQL Server Management Studio and connect to the Analysis Server.
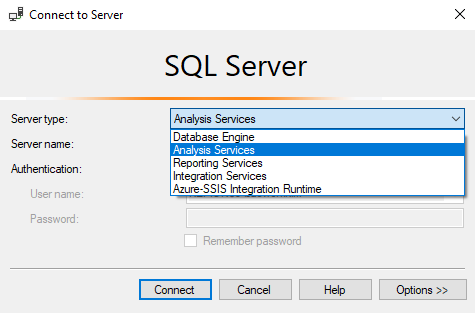
2. Find your target partition (e.g., Actual), right-click it, and select Process.
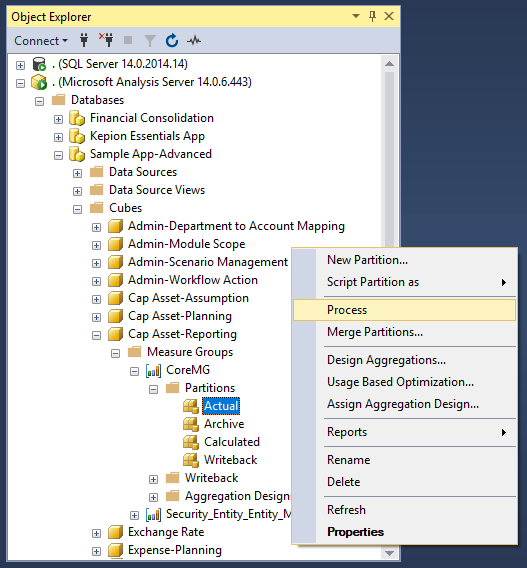
3. Select from the Process Options drop-down as needed.
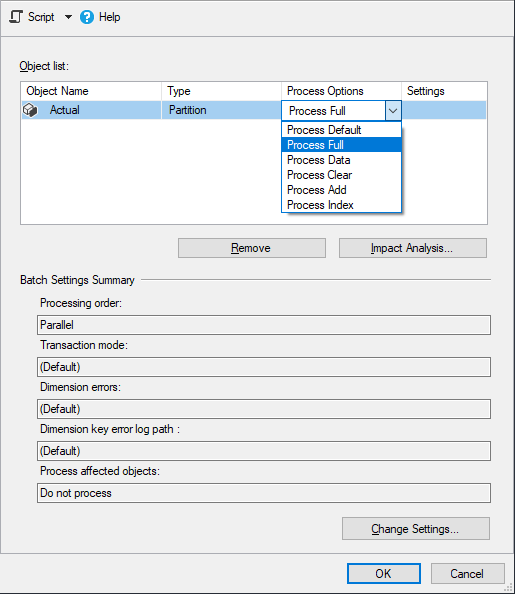
4. Click Script and select Script Actions to Clipboard.
5. Go to the SQL Agent Job and select Properties.
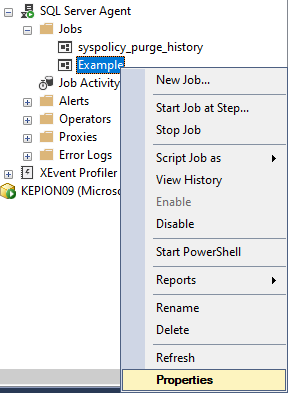
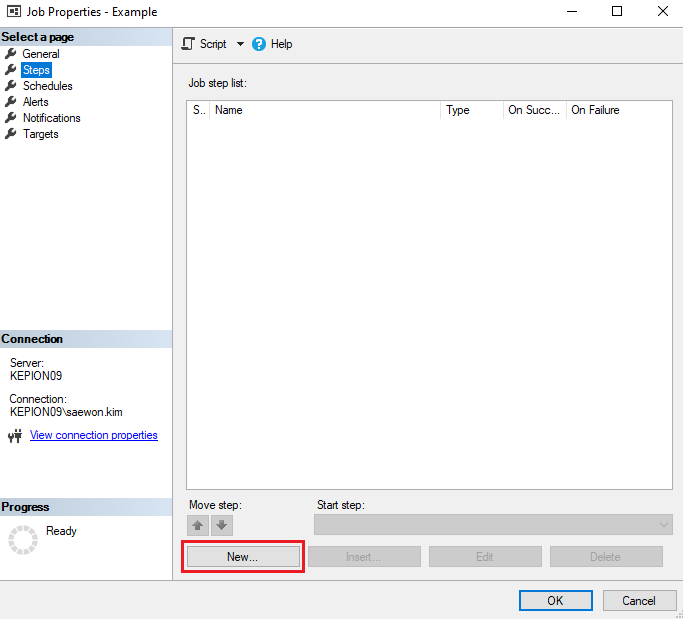
6. Go to Steps and click New...
7. Select SQL Server Analysis Services Command as the Type, enter the server name, paste the code we copied from last step into the Command field.
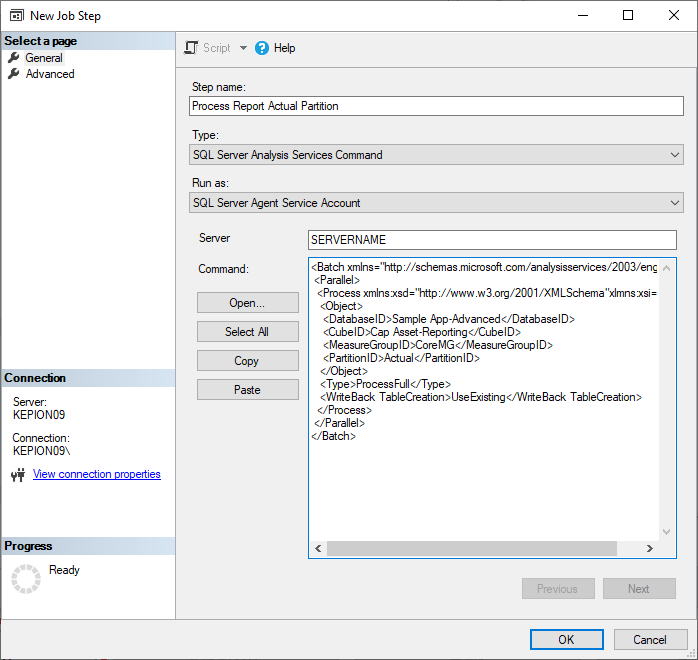
8. Click OK to save.
Example - Process Database
You can follow the same steps to process other objects through SQL Agent Jobs as well:
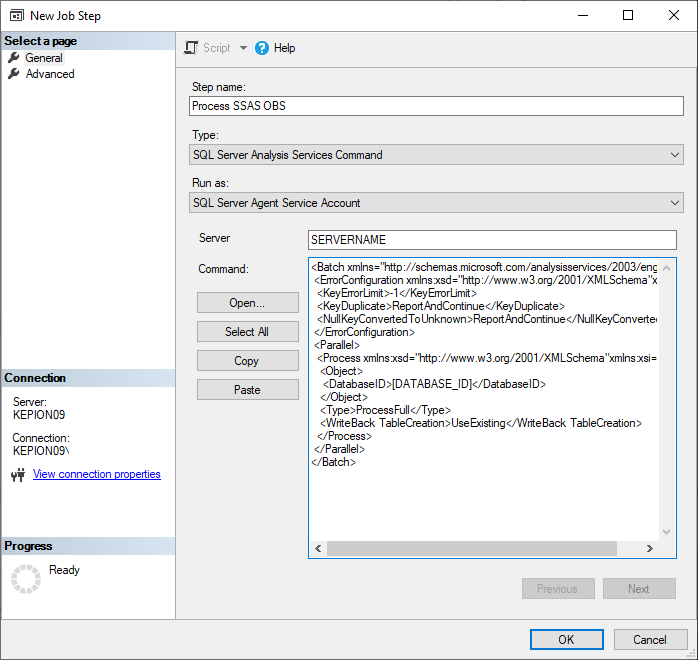
Here is the code. You just need to change [DATABASE_ID] to your Application name.
<Batch xmlns="http://schemas.microsoft.com/analysisservices/2003/engine">
<ErrorConfiguration xmlns:xsd="http://www.w3.org/2001/XMLSchema" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:ddl2="http://schemas.microsoft.com/analysisservices/2003/engine/2" xmlns:ddl2_2="http://schemas.microsoft.com/analysisservices/2003/engine/2/2" xmlns:ddl100_100="http://schemas.microsoft.com/analysisservices/2008/engine/100/100" xmlns:ddl200="http://schemas.microsoft.com/analysisservices/2010/engine/200" xmlns:ddl200_200="http://schemas.microsoft.com/analysisservices/2010/engine/200/200" xmlns:ddl300="http://schemas.microsoft.com/analysisservices/2011/engine/300" xmlns:ddl300_300="http://schemas.microsoft.com/analysisservices/2011/engine/300/300">
<KeyErrorLimit>-1</KeyErrorLimit>
<KeyDuplicate>ReportAndContinue</KeyDuplicate>
<NullKeyConvertedToUnknown>ReportAndContinue</NullKeyConvertedToUnknown>
</ErrorConfiguration>
<Parallel>
<Process xmlns:xsd="http://www.w3.org/2001/XMLSchema" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:ddl2="http://schemas.microsoft.com/analysisservices/2003/engine/2" xmlns:ddl2_2="http://schemas.microsoft.com/analysisservices/2003/engine/2/2" xmlns:ddl100_100="http://schemas.microsoft.com/analysisservices/2008/engine/100/100" xmlns:ddl200="http://schemas.microsoft.com/analysisservices/2010/engine/200" xmlns:ddl200_200="http://schemas.microsoft.com/analysisservices/2010/engine/200/200" xmlns:ddl300="http://schemas.microsoft.com/analysisservices/2011/engine/300" xmlns:ddl300_300="http://schemas.microsoft.com/analysisservices/2011/engine/300/300">
<Object>
<DatabaseID>[DATABASE_ID]</DatabaseID>
</Object>
<Type>ProcessFull</Type>
<WriteBackTableCreation>UseExisting</WriteBackTableCreation>
</Process>
</Parallel>
</Batch>