
Excessive records in a Writeback partition will impact Form and Rule performance. To best manage a huge Writeback partition, we generally recommend archiving historical planning data to a MOLAP partition. But if you want/need all records to remain active, we will cover a method to optimize Application performance as much as possible.
Solution
We're going to store all Writeback data into a static (MOLAP) partition in order to boost performance. Whenever users enter data in the Form (which is posted to the Writeback partition), we'll create corresponding records to offset the static value. To keep the Model clean, we'll need a scheduled task, such as a nightly SQL Agent Job, to consolidate the records from these three partitions in the Static partition.
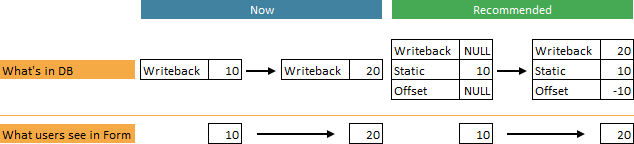
In the diagram above, we can see that end users won't notice any difference in their Form.
Before you Start
We'll use the Application attached below as an example. Given the large set of data, the database will be too large to share, so if you want to follow along, restore the attached database and then run this script to auto-generate all the data.
Create Partitions
1. Go to the Data node of the target Model and click Add to create a partition.
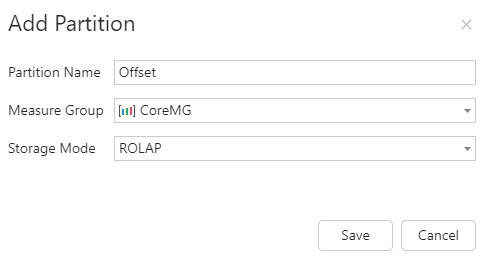
2. Configure the Offset partition as follows:
- Partition Name as Offset
- Measure Group as CoreMG
- Storage Mode as ROLAP
3. Click Save.
4. Create another partition for Static, but make sure the Storage Mode is set to MOLAP.
5. Go to the Rules node and click Add.

6. Configure the SQL Rule as you wish, but make sure the Rule Type is set to SQL.
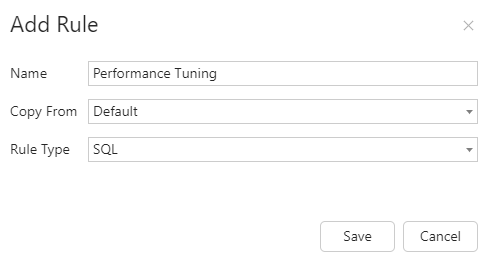
7. Click Save.
8. Write a SQL Rule that calls the USR_CREATE_OFFSET stored procedure. This Rule will execute at Post.
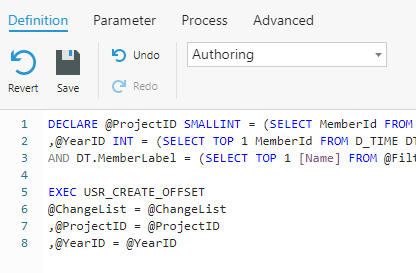
DECLARE @ProjectID SMALLINT = (SELECT MemberId FROM @FilterScope WHERE Dimension = N'Project')
,@YearID INT = (SELECT TOP 1 MemberId FROM D_TIME DT WHERE DT.Granularity = N'Year'
AND DT.MemberLabel = (SELECT TOP 1 [Name] FROM @FilterScope WHERE [Dimension] = N'Time' AND [Hierarchy] = N'FiscalYear'));
EXEC USR_CREATE_OFFSET
@ChangeList = @ChangeList
,@ProjectID = @ProjectID
,@YearID = @YearID
9. Click Save.
In the stored procedure, we use the @ChangeList parameter to pass in only the cells that have been changed. For details of @ChangeList, refer to this article. The stored procedure creates an offset value (highlighted in the illustrator below) to zero out the value in the Static partition if the value exists in Writeback.

Define an Index in the Static Fact Table
In addition, let's define an index in the Static fact table to optimize performance.
1. Open SQL Server Management Studio and locate dbo.F_Performance_CoreMG_Static in you Application database.
2. Right-click the database and select New Index > Non-Clustered Index...
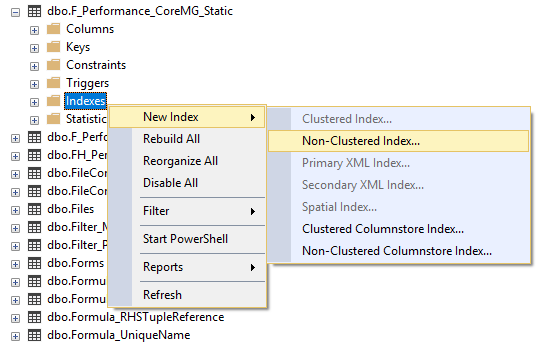
3. Select Add...
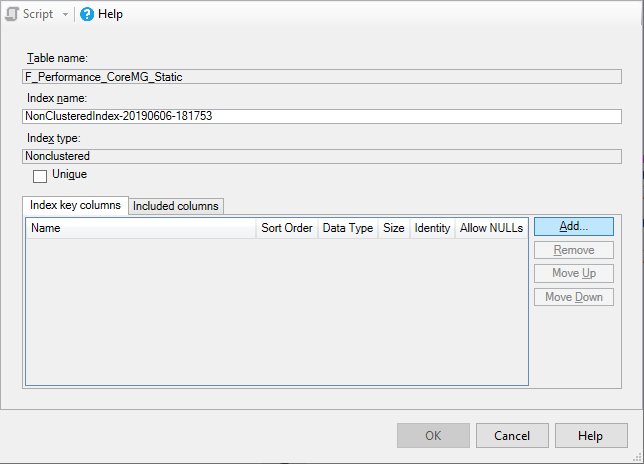
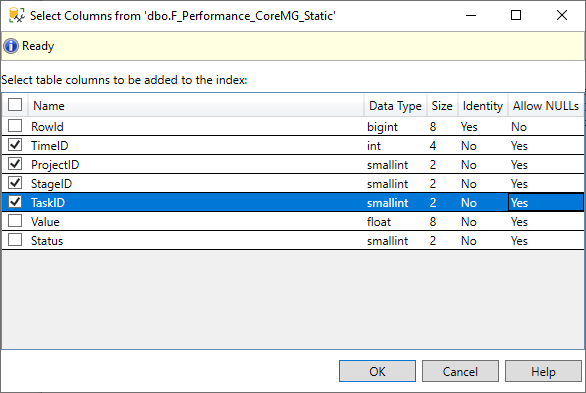
4. Select the table columns to add to the index, which should contain all Model Dimension columns.
Note: The last step that's not included in this example, but crucial for production, is to set up a scheduled SQL Job to clean up and integrate the data. Static records should be replaced by the updated records in Writeback, and then the offset records should be removed.